Este mes vamos a qué componentes intervienen en la arquitectura de una aplicación donde usamos Sapns. Atenea, por ejemplo.
Sapns está construido sobre Turbogears2 y sigue el estándar WSGI, para comunicaciones en aplicaciones web con Python. Lo que se cuenta a continuación se podría conseguir también con Apache2 () + mod_wsgi (http://bit.ly/1jSm0b), por ejemplo, pero nos parece que esta solución es más sencilla de instalar, más ligera y más fácilmente escalable.
Además, se instala en sistemas Linux, concretamente sobre Ubuntu Server, () (la versión 12.04 siempre que sea posible) y normalmente en servidores “virtuales” mejor que “dedicados”. La versión de Python que usamos es como mínimo 2.6.
Arquitectura de una aplicación Sapns
Nginx
()
Es el servidor web y proxy reverso de la aplicación. Es servidor web porque es el encargado de devolver el contenido estático de la aplicación (JS, CSS, imágenes y HTML plano si lo hubiera…que no lo hay).
Es un servidor relativamente nuevo comparado con el “abuelo” Apache2. La razón más poderosa para utilizar Nginx en lugar Apache2 es para Ender, y otros muchas organizaciones, la velocidad y “ligereza” de un sistema frente a otro.
Por otro lado, es un proxy reverso porque sirve las peticiones dinámicas. Lo que ocurre es que cuando el usuario con su navegador solicita una URL para lo que Nginx no encuentra fichero, dicha petición se pasa a un pool de servidores de aplicaciones. Es más simple de lo que parece.
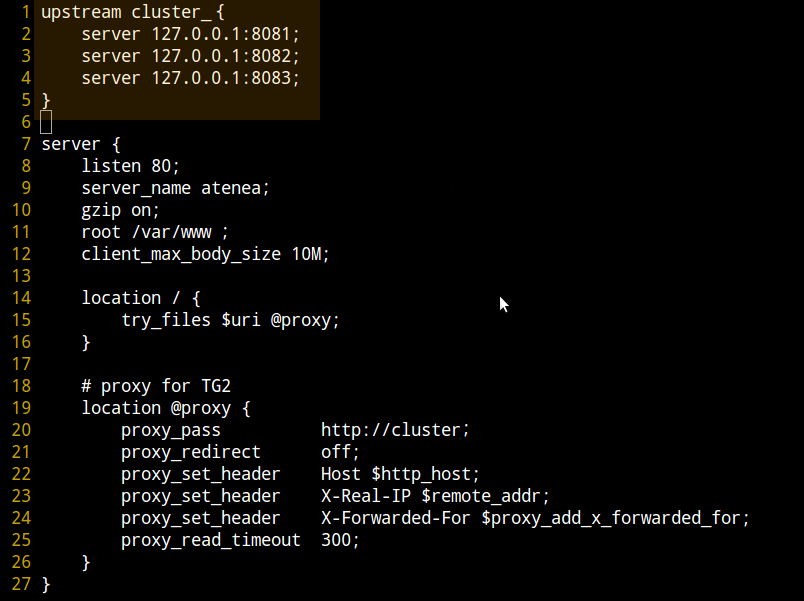
Simplemente, ese pool está formado, en principio, por varios servidores de aplicaciones. Hablaremos más en el siguiente punto de ellos. El caso es que se escoge uno de esos servidores cada vez (división por round robin). Digamos que tenemos 3 servidores de aplicación (A, B y C). La 1ª petición será servida por el A. La 2ª por el B. La 3ª por el C. La 4ª por el A. La 5ª por el B, etc.
En Nginx es posible darle más importancia a uno de los servidores de aplicaciones asignando un peso a dicho servidor. Esto tiene sentido si el pool de servidores no es homogéneo. Digamos que tenemos esto distribuido en varias máquinas. Podríamos asignarle mayor peso a la máquina que fuera mejor (digamos la A). De modo que el ejemplo anterior fuera algo como: 1 -> A, 2 -> A, 3 -> A, 4 -> A / 5 -> B / 6 -> C / 7 -> A, etc. Es decir, que ⅔ de las peticiones fueran servidas por A y el otro ⅓ por B y C.
Supervisor
()
Antes hemos hablado del pool de servidores, pues Supervisor es el encargado de mantener ese pool de servidores. Arrancarlos, pararlos, definir el nº, definir la potencia de cada uno de ellos indicando los workers, etc.
Supervisor es una aplicación hecha en Python que permite gestionar procesos. En el caso de Sapns lo usamos para gestionar los servidores de aplicaciones. En el fichero de configuración indicamos cuántos servidores y qué capacidad (workers) tendrá cada uno, así como dónde se escribirán los logs, etc.
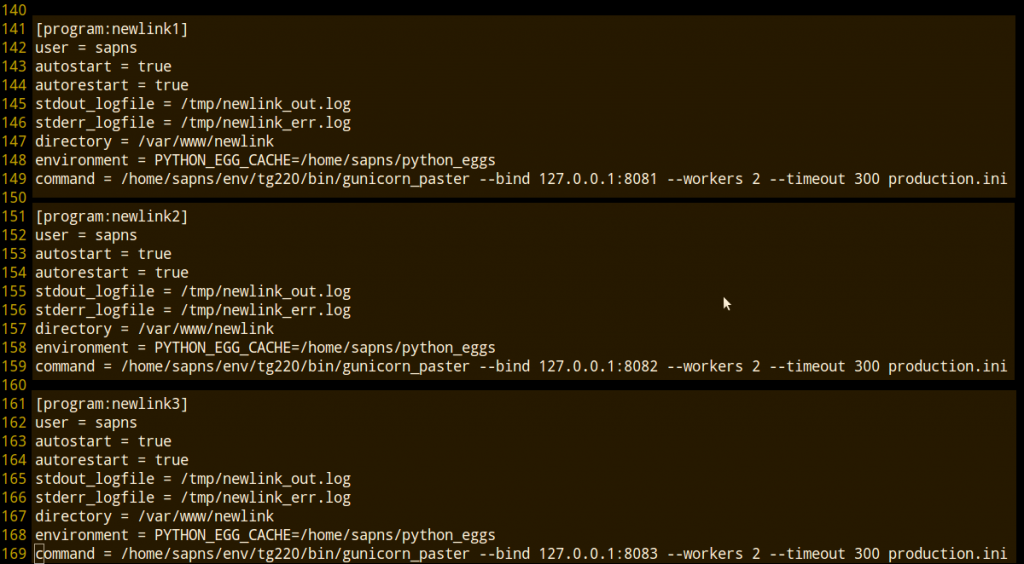
Al final lo que tendremos es una serie de servidores cada uno de los cuales estará esperando peticiones de Nginx en un puerto de la máquina (:8081, :8082, :8083, etc). Si todo está en la misma máquina dichas peticiones sólo podrán venir de localhost, es decir de la IP 127.0.0.1. Esta arquitectura de una aplicación, como hemos contado más arriba, nos permitiría tener cada servidor de aplicación en una máquina diferente.
Gunicorn
()
Es el penúltimo componente de una aplicación Sapns. Es el componente que nos ofrece el servidor de aplicaciones como tal. Lo que hace es servir nuestra aplicación Turbogears2 utilizando el estándar WSGI (). En realidad podríamos decir que el servidor de aplicaciones se contruye con la suma de Supervisor y Gunicorn. Gunicorn es, en realidad, el servidor de aplicaciones, pero utilizamos, además, Supervisor para controlar el número de instancias del servidor de aplicaciones que tendremos y el arranque/rearranque y parada de dichos servidores.
De hecho la información del número de workers no es un parámetro de Supervisor sino de Gunicorn. La línea command nos permite definir dichos parámetros de entrada a Gunicorn.
PostgreSQL y MongoDB
Son las bases de datos del sistema. PostgreSQL () contiene la mayor parte de la información y MongoDB (http://bit.ly/VCpR5) se utiliza como sistema auxiliar de almacenamiento de datos estructurales o sistémicos.
PostgreSQL es una “típica” base de datos relacional y MongoDB es una base datos NoSQL () basada en “documentos”. Ambas están, en principio, configuradas para escuchar sólo peticiones locales, con lo que es imposible el acceso directo a los datos. Si distribuiéramos el servicio de bases de datos en “otras” máquinas, simplemente habría que configurar para que las peticiones sólo pudieran venir de cierta (o ciertas direcciones IP).
Turbogears2
()
Es él último componte y el que cambia de una organización a otra. En este punto hay gente que usa Django () o Pyramid () o alguno de los frameworks web Python que existen ahí fuera (http://bit.ly/3jxUSJ).
Este el código de la aplicación. Lo que finalmente es ejecutado, en este caso, por Gunicorn. En otro momento hablaremos de los componentes más importantes que usamos dentro de Python.
Conclusiones
Más allá de las elecciones de cada nivel lo importante de la arquitectura de una aplicación es su capacidad para ser escalada. Es decir, que si necesitamos procesar más peticiones por segundo podemos distribuir los componentes en varias máquinas para aumentar la capacidad del sistema globalmente.
Por ejemplo tener Nginx en una máquina y los servidores de aplicaciones en otra u otras. Podríamos tener también la base de datos (PostgreSQL y MongoDB) en otro servidor diferente. Todo con tal de construir una aplicación capaz de responder a cualquier contingencia o situación de capacidad que se necesite.