Cuando se desarrolla «en grupo» hacen faltan varias herramientas para trabajar de una forma eficiente. Una de ellas es la utilización de algún sistema de versiones (Subversion, CVS, mercurial, git, etc), y la otra es la compilación automática, lo que habréis visto muchas veces como «nightly builds».
Estos sistemas nos permiten por un lado ahorrar tiempo (el programador no tiene que preocuparse de compilar todo el código que forma un producto/proyecto cada vez que hace algún cambio), y por otro generar una salida uniforme e integrada de todos los posibles cambios que se han producido (los cambios de varios programadores «confluyen» en único producto compilado que incluye las correcciones y mejoras de todos aquellos). Estos sistemas, lógicamente, están integrados con los sistemas de control de versiones, de modo que los cambios en uno sean detectados por el otro.
Nosotros utilizamos un sistema «free» llamado Hudson. Hudson es una aplicación web (servlet) sobre Apache o Glass fish que nos permite compilar automáticamente nuevas versiones con los cambios que hacemos en el código.
Para que Hudson genere nuevas versiones de un módulo (métodos, aplicaciones, …) tenemos que configurar un trabajo o job que le indique qué tiene que hacer para generar dicho módulo compilado.
En ender creamos (y configuramos) un job por método, por aplicación o por test, esto hace cada «pieza» independiente (hasta cierto punto) del resto. Debemos identificar cada uno de estos jobs con un nombre único. Normalmente estos nombres son iguales al nombre del módulo. Cuando hay diferentes módulos con el mismo nombre utilizamos un prefijo para el nombre. Por ejemplo,
Alu01 en la vista Turno
SQL_Alu01 en la vista SQL_Turno
Un trabajo en Hudson puede estar o no dentro de una vista (view). Una vista es como un saco dentro del que agrupar ciertos trabajos que están relacionados entre sí. En nuestro caso, esa relación siempre es porque todos ellos pertenecen a un mismo producto/proyecto. No es obligatorio que un trabajo esté dentro de una vista, pero nos permite ver rápidamente todos los trabajos relacionados con un producto/proyecto. Estas vistas son las pestañas que aparecen cuando entramos en la home de Hudson (ARGOS, AFORO, Olympo, IHMSI, etc).
Para crear un nuevo trabajo pinchamos en «New Job» en la parte superior izquierda del sitio web de Hudson. Si nos encontramos en una vista, dicho trabajo se creará bajo esa vista. Si estamos en la home se creará sin vista asociada, y posteriormente lo podremos encontrar bajo la vista general «All«.

Una vez creado (y guardado) un trabajo para acceder de nuevo a la configuración nos dirigiremos a dicho trabajo, pincharemos en él y despúes elegiremos «Configure«, en el menú de la izquierda.

Para configurar un nuevo trabajo tenemos que tener en cuenta principalmente lo siguiente:
- ¿Dónde está el código?
- ¿Cómo se compila el código?
- ¿Cuándo debe compilarse el código?
1. ¿Dónde está el código?
Hablábamos más arriba que los sistemas de control de versiones y los de compilación automática «deben» estar integrados. Para ello tenemos que indicar la ruta en el repositorio donde se encuentra dicho código. Esto implica indicar todo el código necesario para compilar dicho módulo, excepto los componentes comunes que ya estén instalados en el servidor donde está corriendo Hudson. Es decir, los componentes que tenemos instalados en Delphi.
Bajo el epígrafe «Source Code Management» tenemos que poner cada «pieza» del código que necesitamos para la compilación.

En el ejemplo estamos diciendo que se descargen dos «piezas» de código: AFOROFunc01 y Unidades Compartidas, cada una con su ruta correspondiente en el repositorio y un nombre de carpeta local.
svn://peter/Aforo/Trunk/Métodos/AFOROFunc01 -> Source
svn://peter/Aforo/Trunk/Métodos/Unidades compartidas -> Unidades Compartidas
svn:// indica el protocolo Subversion
/peter indica el servidor
/Aforo/Trunk/Métodos/AFOROFunc01 indica la ruta dentro del repositorio que reside en el servidor peter.
Cómo se puede ver en la imagen, Hudson permite utilizar dos sistemas de control de versiones diferentes: CVS y Subversion, o no usar ninguno cuando se trata de trabajos que no dependen de cambios en el código (test diarios, por ejemplo).
2. ¿Cómo se compila el código?
Hudson utiliza órdenes de shell para compilar cada uno de los trabajos. Por tanto, para compilar un trabajo utilizamos el ejecutable del compilador incluido en las diferentes distribuciones de Borland Developer Studio (en nuestro caso BDS 2006). Dicho compilador se encuentra en la carpeta donde esté instalado BDS, normalmente «C:Archivos de programaBDS4.0Bindcc32.exe».
dcc32.exe [options] filename [options]
Todas las opciones disponibles se pueden ver ejecutando el compilador sin ningún parámetro.

Como estamos usando la versión de línea de comando ciertos datos de configuración que rellenamos en el IDE de Delphi los tenemos que rellenar a mano en el fichero «dcc32.cfg«, situado en la misma ruta que el propio compilador.
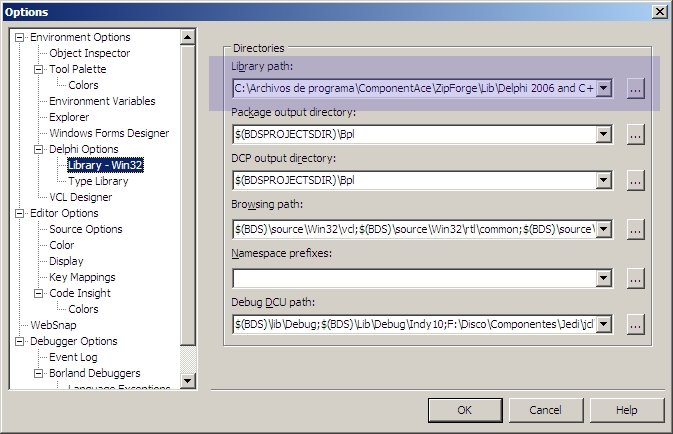
Las opciones para «Library path» se indican utilizando la opción -u. Por ejemplo,
-u»e:archivos de programaBorlandBDS4.0lib»;»e:archivos de programaBorlandBDS4.0libObj»;»F:ComponentesPackage 2006″;…
-u»d:ComponentesMiComponente»;»d:ComponentesOtroComponente»;…
Aquí debemos poner las rutas a todos los componentes que tenemos instalados y que son necesarios para compilar nuestros proyectos.

Las opciones para «Conditional defines» se definen utilizando -D. Por ejemplo,
-DLEVEL3;LEVEL4;LEVEL5;LEVEL6;XDOM_2_3
-DDebug
-DVersionDePrueba
Se trata de opciones de compilación controladas por instrucciones como {$IFDEF}, {$IFNDEF}, etc. Es equivalente a poner {$DEFINE —–} en el código.
Las opciones para «Unit aliases» se definen utilizando -a. Por ejemplo,
-aWinTypes=Windows;WinProcs=Windows;DbiProcs=BDE;DbiTypes=BDE;DbiErrs=BDE
Ésta última ya está definida por defecto en el fichero «dcc32.cfg» y probablemente no tendremos que modificarlo.
Cada job en Hudson tiene su propia carpeta en disco y dentro de ella se descarga (desde el repositorio) el código, como hemos visto en el apartado anterior.

Bajo el epígrafe «Build» disponemos de un cuadro de texto donde escribiriemos las órdenes necesarias para compilar el módulo. Estos comandos siguen la estructura de un archivo Batch (.BAT) de Windows. De hecho, Hudson genera un archivo .bat con el contenido de «Command» y lo ejecuta cada vez que necesita compilar el job.
Partimos de la carpeta propia del trabajo, así que lo primero que tenemos que hacer es entrar en la carpeta «Source» (recuerda que es el nombre que le hemos dado a una de las piezas del código)
cd Source
y ejecutar un par de órdenes
«e:Archivos de programaborlandbds4.0bindcc32» -w+ -h AFOROFunc01
La primera ejecuta el compilador de Delphi para el proyecto correspondiente (AFOROFunc01). Esto generará un fichero .DLL o un fichero .EXE, en nuestro caso AFOROFunc01.dll.
«e:Archivos de programaWinrarrar.exe a AFOROFunc01.rar AFOROFunc01.dll
La segunda línea es opcional y nos permite comprimir el resultado obtenido en la compilación (AFOROFunc01.dll) en un archivo más pequeño. De esta manera cuando descargamos un módulo podemos elegir la versión comprimida y tardaremos menos.
Una vez compilado el código tenemos que indicarle a Hudson qué debe guardar de los archivos que se producen. Esto se hace bajo el epígrafe «Post-build Actions«.

Tenemos que marcar el check «Archive the artifacts». En el cuadro de texto rotulado como «Files to archive» configuramos qué ficheros (artifacts) queremos que se almacenen. Hudson guardará un histórico (según el número de versiones disponibles que indiquemos) de dichos «artefactos», con lo que podríamos recuperar una versión anterior.
3. ¿Cúando debe compilarse el código?
Los trabajos se pueden ejecutar tras la ejecución existosa de otro/s trabajo/s (Build after other projects are built), cada cierto tiempo (Build periodically) o cada cierto tiempo comprobando cambios en el código (Poll SCM).
Todo esto se configura bajo el epígrafe «Build Triggers«.

En la opción «Build after other projects are built» indicamos una lista con uno o varios trabajos (de Hudson) separados por comas. En las opciones «Build periodically» y «Poll SCM» se configuran utilizando el campo «Schedule«. La diferencia entre ellos es que uno se compila siempre y otro sólo si ha habido cambios en el código.
En el campo «Schedule» se trata de escribir la configuración para cinco datos separados por espacios o tabuladores. Normalmente sólo hay una línea pero podríamos tener varias. Esta configuración es similar a la de crontab en sistemas *nix.
[MINUTE] [HOUR] [DOM] [MONTH] [DOW]
MINUTE (minuto) [0, 59]
HOUR (hora) [0, 23]
DOM (day of month – día del mes) [1, 31]
MONTH (mes) [1, 12]
DOW (day of the week – día de la semana) [0, 7], donde 0 y 7 significan Domingo.
Si indicamos * (asterisco) significa «todo». Por ejemplo, si ponemos * en la columna de los minutos, significa «cada minuto». Si lo ponemos en el «día de la semana» significa «todos los días de la semana», etc.
Algunos ejemplos serían:
0 20 * * *
Todos los días a las 20:00
0 20 * 1 *
Todos los días de Enero a las 20:00
30 19 1 * *
30 19 15 * *
Todos los días 1 y 15 a las 19:30
Para trabajos en los que elegimos «Poll SCM» la configuración por defecto (* * * * *) suele ser la más utilizada. Es decir, se comprueba el código «cada minuto». Sólo en el caso de que la compilación de ciertos trabajos lleve mucho tiempo, podemos elegir que dichos trabajos más «costosos» se compilen «fuera de horario».
Una vez hemos configurado todo pulsamos Save en la parte inferior de la página.